Throughout my career I’ve had the pleasure of building on and maintaining a variety apps, all with very different setups. A common approach is having constantly running servers to power a backend/API, an always-on database and separate code bases tailored for web and native (iOS, Android etc.).
While this setup works well, it can end up being expensive and may not be the ideal approach for a start-up or low traffic applications with minimal/short bursts of activity:
- A lot of cloud computing providers charge by the minute for running servers, even with auto-scaling you’re looking at potentially paying for computing resources you’re not using at off peak and quiet times.
- If you don’t have the resources to manage backups and fail-safes for your data store in-house, it makes sense to go with a managed DB service like RDS. But these can be pricey, even for smaller instances.
- Developing separate native apps has been the only way to tap into a lot of native features for long time. This means maintaining two or more separate code bases to support desktop and mobile. Depending on the frameworks that are chosen, this could also require developers with different skillets to maintain each. Plus any updates to how your app works have to be duplicated across multiple code bases, going against a key software development principle “Do not repeat yourself” (DRY).
So what’s the alternative? Let’s approach the back end and front end solutions separately…
Backend alternative: Serverless API and Database
The concept behind serverless is that we won’t reserve or pay for any computing power until we need it. So if nobody is using your app, your API incurs no computing power and just sits there as static code. But when someone interacts with your app, computing resource gets provisioned for your code to fulfil requests. Depending on the provider, it might be kept running for a little while in case there are more requests.
Some examples of serverless functions are AWS Lambda and Google Cloud Functions. With AWS Lambda, no configuration is required for scaling, although you can customise the levels of concurrency you want to support. There are also serverless data stores like DynamoDB and Firestore.
I recently wrote an article that can get you started with deploying a performant serverless Python API to AWS.
Caveats
One thing to be aware of with this approach is cold starts. This is the time it takes to spin up computing resource and make a service accessible if it’s been inactive. Cold start time is influenced by a number of factors including language and package size. AWS does keep Lambdas available for a while after use, although the time they remain in play varies.
The good news is that we can reduce or mitigate this problem in a couple of ways:
- Keeping the lambda “warm” with provisioned concurrency.
- You can configure lambda to have one or more instances warm and always ready to go. Although, if you experience a high volume of requests, it’s possible more will have to be spun up to meet demand. This action of scaling up would incur cold start for some users.
- You can configure lambda to have one or more instances warm and always ready to go. Although, if you experience a high volume of requests, it’s possible more will have to be spun up to meet demand. This action of scaling up would incur cold start for some users.
- Keeping your APIs lightweight and single purpose.
- A microservice architecture could really come to the rescue here. If you have an API handling multiple things (e.g. web shop and user account management), consider making these separate APIs/services. This way each service can scale independently, dividing packages and dependencies across services to reduce cold start times.
- A microservice architecture could really come to the rescue here. If you have an API handling multiple things (e.g. web shop and user account management), consider making these separate APIs/services. This way each service can scale independently, dividing packages and dependencies across services to reduce cold start times.
- A mixture of the above.
- Some services might be more time critical than others. In the example of the shop and user account services, I could allocate provisioned concurrency to keep the shop service warm and leave the less frequently used account system to scale independently.
Tip: It’s worth investing time in visual loading states on your front-end (e.g. spinners and skeletons) for when a user encounters a cold start.
Front-end alternative: Progressive Web Apps (PWA) and Trusted Web Activities (TWA)
Broadly, PWAs are a type of web app with a set of tools to empower developers to build web apps with experiences on par with native apps. As far as a user’s concerned it’s just like any other website, but in the background, a service worker downloads the app’s assets onto the user’s device.
This means the user doesn’t have to keep retrieving assets, this can also be leveraged to provide offline experiences. A PWA can also cache the responses of network requests too (see this article on PWA caching strategies).
For React.js developers, one way of getting started with a PWA quickly is using create-react-app’s PWA template. This sets up a basic app with a manifest and a service worker ready to be enabled.
Deploying as a native app
For a long time PWAs were not supported in iOS or Android app stores. A couple of years ago, Google introduced Trusted Web Activities (TWAs), which support embedding a PWA into a native Android app. So in this scheme you’d create an empty shell of an app, and use your TWA to load your verified PWA. For building iOS app packages to publish on the Apple store, check out PWABuilder’s freely available iOS store package tool.
Caveats
While Microsoft and Google have strong PWAs support in their stores, the same cannot be said for Apple. There are a few parts of PWA that Apple still doesn’t support (including Push Notifications), PWABuilder cover this in the documentation for their tool.
If this is a deal breaker for you, writing apps specifically for native might be your best bet. For more detail on what’s supported, you can check out this detailed breakdown for Safari/iOS and this breakdown for Chrome/Android.
Putting the theory to the test…
A few years ago I put a rough game together to play with some friends, where players were asked to come up with truths about themselves that other people wouldn’t know, and at each round we would take it in turns to read a statement that would either be one of our truths, or a made up lie. We would then earn points for deceiving other players.
The game was very limited in that it only worked on one device and relied on text files instead of a UI for setup. I decided to revisit this and build it with the tools discussed in this article, and ended up with Fact or Fib. It’s an online multiplayer game with user accounts, lobby creation and real time events synced across client devices.
It’s been up and running for several months, and it’s had a good few tests. One game had around 17 of us playing for a couple of hours. It runs smoothly (for the most part bar a few niggles!).
So far I haven’t paid a single penny for running it (other than the domain name and DNS costs).

Let’s dig into…
The stack
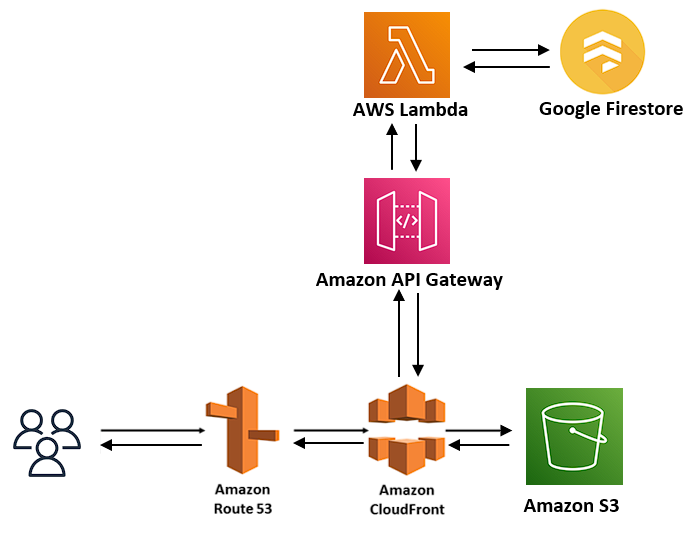
- Google Cloud Firestore for data storage, and Firebase for registration and authentication.
- A Python Lambda based API using the FastAPI framework, running on lambda served via API Gateway.
- I used this template from my last article as a jumping off point.
- The front-end app interacts with the Firestore database via the Python API
- Leaning on Firestore’s real time updates feature for syncing real time events across client devices.
- React typescript front-end, leaning on create-react-app’s PWA template
- Front-end deployed to Amazon S3, served via the CloudFront CDN
- Automatic front-end deployments are triggered on a merge to a specified branch with AWS Amplify
I might have been able to get away without implementing an API at all, using Firestore’s features and ability to set granular permissions could have facilitated the same effect. However, doing this would have tied me into using Firestore. Abstracting Firestore within the API means that I could change the data store, or use additional datastores later down the line if I wanted to.
Another good alternative serverless data store might have been AWS DynamoDB, but for my usecase, the real time updates feature that comes packed with Firestore gave it the edge.
To summarise…
If you’re a start-up looking to bring a new app to web and app stores, want to avoid juggling multiple code bases, or sinking money on infrastructure if the app doesn’t get used a lot, this might just be the stack for you!
But if your idea relies on native features not supported by PWA, or you’re expecting high volumes of fairly continuous activity for your app, an always-on backend stack might be a better choice.